
摘要:条件随机场常用于序列标注、数据分割等自然语言处理任务中,此外其在中文分词、中文人名识别和歧义消解等任务中也有应用。本文基于笔者在做语句识别序列标注过程中,对条件随机场产生的了解。全篇内容主要源于自然语言处理、机器学习、统计学习方法和部分网上资料对CRF的相关介绍,最后由笔者进行大量研究整理后汇总成体系知识。本章首先介绍条件随机场的相关概念,然后结合实例以期让读者深入理解条件随机场的应用。(本文原创,转载必须注明出处.)
条件随机场介绍
条件随机场(Condition Random Fields),简称CRF
条件随机场概念:条件随机场就是对给定的输出标识序列Y和观察序列X,通过定义条件概率P(X|Y),而不是联合概率分布P(X,Y)来描述模型。
概念解析:
标注一篇文章中的句子,即语句标注。使用标注方法BIO标注,B代表句子的开始,I代表句子中间,O代表句子结束。观察序列X就是一个语料库(此处假设一篇文章,x代表文章中的每一句,X是x的集合),标识序列Y是BIO,即对应X序列的识别。从而我们可以根据条件概率P(标注|句子),推测出正确的句子标注。显然,这里我们针对的是序列状态,即CRF是用来标注或划分序列结构数据的概率化结构模型的。CRF在自然语言处理和图像处理领域都得到了广泛的应用,我们可以把它看作是无向图模型或者马尔可夫随机场。
生产式模型与判别式模型
有监督机器学习方法可以分为生成方法和判别方法:
生产式模型:直接对联合分布进行建模,如:混合高斯模型、隐马尔科夫模型、马尔科夫随机场等
判别式模型:对条件分布进行建模,如:条件随机场、支持向量机、逻辑回归等
生成模型优缺点介绍
优点:
- 生成给出的是联合分布,不仅能够由联合分布计算条件分布(反之则不行),还可以给出其他信息。如果一个输入样本的边缘分布很小的话,那么可以认为学习出的这个模型可能不太适合对这个样本进行分类,分类效果可能会不好。
- 生成模型收敛速度比较快,即当样本数量较多时,生成模型能更快地收敛于真实模型。
- 生成模型能够应付存在隐变量的情况,比如混合高斯模型就是含有隐变量的生成方法。
缺点:
- 天下没有免费的午餐,联合分布是能提供更多的信息,但也需要更多的样本与计算;尤其是为了更准确估计类别条件分布,需要增加样本的数目。而且类别条件概率的许多信息是我们做分类所用不到的,因而如果我们只需要做分类任务,就浪费了计算资源。
- 另外,实践中多数情况下判别模型效果更好。
判别模型优缺点介绍
优点:
- 与生成模型缺点对应,首先是节省计算资源。另外,需要的样本数量也少于生成模型。
- 准确率往往较生成模型高。
- 由于直接学习,而不需要求解类别条件概率,所以允许我们对输入进行抽象(比如降维、构造等),从而能够简化学习问题。
缺点:
- 没有生成模型的上述优点。
简单易懂的条件随机场
CRF的形式化表示
设G=(V,E)为一个无向图,V为结点的集合,E为无向边的集合。 ,即V中的每个结点对应一个随机变量Yv,其取值范围为可能的标记集合{Y}。如果观察序列X为条件,每一个随机变量都满足以下马尔可夫特性:
,即V中的每个结点对应一个随机变量Yv,其取值范围为可能的标记集合{Y}。如果观察序列X为条件,每一个随机变量都满足以下马尔可夫特性:

其中,w–v表示两个结点在图G中是邻近结点,(X,Y)为条件随机变量。
以语句识别的案例理解条件随机场的形式化表示,如图12-1所示。
G=(V,E表示识别语句:【我爱中国】的标注是一个无向图,X为观察序列,Y为标注序列,V是每个标注状态的结点。E的无向边,边上的权值为概率值。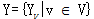 表示每个X的Y的标注,如:X1:我,y1:O,y2:I,y3:B;取值范围
表示每个X的Y的标注,如:X1:我,y1:O,y2:I,y3:B;取值范围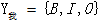 ,而
,而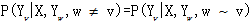 中w—v表示我与爱是相邻的结点。这样的(X,Y)为一个条件随机场,真正的标注再采用Viterbi算法,如:
中w—v表示我与爱是相邻的结点。这样的(X,Y)为一个条件随机场,真正的标注再采用Viterbi算法,如:
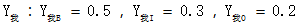
寻求最大概率即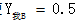 ,记录下我的标注路径,同理可知:
,记录下我的标注路径,同理可知:
</p>
如上便是对条件随机场与Viterbi算法的综合运用,其中Viterbi标注问题本质是隐马尔可夫模型三大问题之解码问题的算法模型,具体参考(揭秘马尔科夫模型系列文章)
CRF的公式化表示
在给定的观察序列X时,某个待定标记序列Y的概率可以定义为
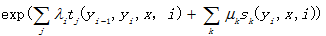
其中 是转移概率;
是转移概率;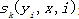 是状态函数,表示观察序列X其中i的位置的标记概率;
是状态函数,表示观察序列X其中i的位置的标记概率;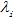 和
和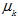 分别是t和s的权重,需要从训练样本中估计出来。
分别是t和s的权重,需要从训练样本中估计出来。
实例解析:
我爱中国,其中x2是爱字。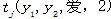 表示在观察状态2中,我到爱的转移概率;其中j∈{B,I,O},可知
表示在观察状态2中,我到爱的转移概率;其中j∈{B,I,O},可知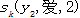 的生成概率或者发射概率的特征函数。用观察序列{0,1}二值特征b(x,i)来表示训练样本中某些分布特征,其中采用{0,1}二值特征即符合条件标为1,反之为0;如图12-3所示。
的生成概率或者发射概率的特征函数。用观察序列{0,1}二值特征b(x,i)来表示训练样本中某些分布特征,其中采用{0,1}二值特征即符合条件标为1,反之为0;如图12-3所示。
</p>
为了便于描述,可以将状态函数书写以下形式:
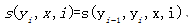
特征函数:
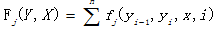
其中每个局部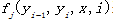 特征表示状态特征,
特征表示状态特征,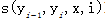 或者专业函数
或者专业函数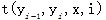 ,由此条件随机场的定义条件概率如下:
,由此条件随机场的定义条件概率如下:
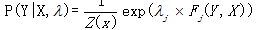 ,
,
其中分母为归一化因子:
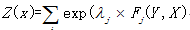
深度理解条件随机场
理论上标记序列描述一定条件的独立性,G图结构是任意的,对序列进行建模可形成最简单、最普通的链式结构图。结点对应标记序列X中元素,CRF链式图如21-5所示:
如果上图两种表示是一致的,其中图链式句子标注是图链式2的实例化,那么有的读者可能会问为什么上面图是这种而不是广义的图。其实这是因为观察序列X的元素之间并不存在图结构,没有做独立性假设,这点非常容易理解。诸如图中“我爱中国”,其中b表示反射概率而t是转移概率,线上的数值表示权值即概率值。如图3,我的发射概率0.7,我到爱的转移概率0.5。通俗讲,我和爱两个字是有关联的,而非独立的。
参考文献
- 数据挖掘十大算法:https://wizardforcel.gitbooks.io/dm-algo-top10/content/apriori.html
- 中文维基百科:https://zh.wikipedia.org/wiki/%E5%85%88%E9%AA%8C%E7%AE%97%E6%B3%95
- GitHub:https://github.com/BaiNingchao/MachineLearning-1
- 图书:《机器学习实战》
- 图书:《自然语言处理理论与实战》
完整代码下载
源码请进【机器学习和自然语言QQ群:436303759】文件下载:

作者声明
本文版权归作者所有,旨在技术交流使用。未经作者同意禁止转载,转载后需在文章页面明显位置给出原文连接,否则相关责任自行承担。


