
摘要:本文写作的初衷源于基于HMM模型序列标注的一个实验,在实验完成之后,如果迫切想知道采用的序列标注模型好坏,有哪些指标可以度量。于是,就产生了对这一专题进度的学习总结,这样也便于其他人参考,节约大家的时间。本文依旧旨在简明扼要地梳理出模型评估核心指标,关键以期达到实用的目的。本章首先介绍基于统计角度的模型评估,然后介绍模型评估的方法,最后对模型选择进行介绍。(本文原创,转载必须注明出处.)
统计角度介绍模型概念
算法模型
概念简述
李航《统计学习方法》一书:统计学习方法是由模型、策略和算法构成的,即统计学习方法的三要素构成,简化:方法=模型+策略+算法
维基百科对数学模型描述:数学模型是对所描述的对象用数学语言所作出的描述和处理。
百度百科对策略描述:策略式学习是一项复杂的智能活动,学习过程与推理过程是紧密相连的。按照学习中使用推理的多少,机器学习所采用的策略大体上可分为4种——机械学习、通过传授学习、类比学习和通过事例学习。学习中所用的推理越多,系统的能力越强。
单从定义看,不免让人一头雾水,究竟何为模型?还是没有明确的概念。下文将以数学描述以及形式化阐述来解决这个问题。首先解决了什么是模型,咱们才能进行模型好坏指标的评价,进而选择适合的学习模型。
模型:所有学习的条件概率分布或者决策函数。
模型的假设空间:包含所有有可能的条件概率分布或者决策函数。
实例解析
假设决策函数是输入变量的线性函数,模型的假设空间就是这些线性函数构成的函数集合,假设空间中的模型一般为无穷多个。【现实应用:假设解决序列词性标注的的函数模型M,模型假设空间中由不同参数构成的M模型。(不是很严谨,辅助理解。)】
形式化表示:假设空间F表示,假设空间可以为决策函数的集合;
x,y在输入空间X和输出空间Y上的变量,这时F通常由一个参数向量决定的函数族表示;
参数向量θ取值于n维欧氏空间 ,称为参数空间。
假设空间也可以定义为条件概率集合:
其中x和y是定义在输入空间X和Y上的随机变量,这时F通常是一个参数向量决定的条件概率分布族;
参数向量θ取值于n维欧氏空间,称为参数空间。
注意:由决策函数表示的模型为非概率模型(如上述F函数),由条件概率表示的模型为概率模型(如上述y=f(x)函数)。
模型评估和模型选择
训练误差和测试误差
好的模型的特征:对已知数据和未知数据都有很好的预测能力。
学习方法评估标准:基于损失函数的模型训练误差和测试误差为指标。
假设学习到的模型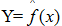 ,训练误差是模型 关于训练数据集的平均损失:</p>
,训练误差是模型 关于训练数据集的平均损失:</p>
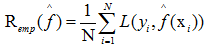
其中N是训练样本容量。
测试误差是模型关于测试数据集的平均损失:
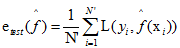
其中N’是训练样本容量。
实例
若损失函数是0-1损失的时候(0-1损失参考具体相关知识),测试误差就变成了常见的测试数据集上的误差率。
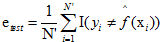 ,这里的I是指示函数,即
,这里的I是指示函数,即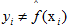 时为1,否则为0。
时为1,否则为0。
相应的,常见的测试数据集上的准确率是:
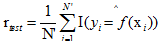 ,这里的I是指示函数,即
,这里的I是指示函数,即 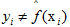 时为1,否则为0。
时为1,否则为0。
显然: 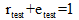
实例解析
根据误差率和准确率可知,测试误差反映了学习方法对未知测试数据集的预测能力。测试误差小的方法具有很好的预测能力,能更有效地预测。通常将学习方法对未知数据的预测能力称为泛化能力。
由此我们可以应用到现实的NLP模型中。诸如分类模型,当测试误差更小的时候,分类更加准确;聚类模型中,当测试误差较小时候,聚类效果更好等等。因此,我们为了追求较小的测试误差,就要在训练上下功夫。但是,一味苛求训练效果好、训练误差小,以至于所选择的模型复杂度非常高,这样的低训练误差就一定能换回好的预测吗?事实上这就容易出现过拟合现象,如何避免过拟合选择更好的模型?下节继续。
过拟合与欠拟合的模型选择
何时进行模型选择?
当假设空间含有不同复杂度(如:不同的参数个数)的模型时,就要面临模型选择问题,以期我们表达出的模型与真实的模型(参数个数)相同或相近。
过拟合:一味追求提高对训练数据的预测能力,所选择模型的复杂度往往比真实模型高,此现象就是过拟合。
过拟合指学习时选择的模型包含的参数过多,以至于出现模型对现有数据预测得好,但是对未知数据预测能力较差。模型选择准则是在避免过拟合的前提下尽可能地去提高模型预测的能力。
实例
给出一个训练数据集 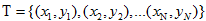 和一个M次多项式的模型
和一个M次多项式的模型
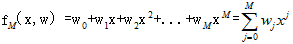
完成下面10个数据点的拟合。
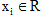 是输入序列集x的观察值
是输入序列集x的观察值
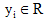 是输出序列集y的观察值
是输出序列集y的观察值
M 次项式是解决问题的模型
W为参数
解决如上问题按照经验风险最小化策略求解参数即可,即数学表达:
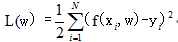
损失函数为平方损失,1/2是便于计算。然后将模型公式和训练数据代入风险最小化公式:
 ,最后采用最小二乘法(过程略)求解。
,最后采用最小二乘法(过程略)求解。
实例分析
如上图给出M=0,1,3,9的多项式函数的拟合情况。当M=0时,多项式变成了一个常数,数据拟合表现很差;当M=1时,多项式曲线为一条直线,拟合依旧差;当M=9时,多项式通过每一个点,训练误差0。从训练数据拟合角度分析,M=9时效果最好,但是训练数据本身存在很多噪音,对未来数据预测能力差,达不到预期的效果。这就是过拟合,虽然训练数据表现好但是未知数据预测差。当M=3时,多项式曲线对训练数据拟合效果比较好,对未知数据拟合也很好,其模型也简单,可以选择。总结:模型选择时,不仅仅考虑对已知数据的预测能力,还有考虑对未知数据的预测能力。
训练误差和测试误差与模型复杂度的关系如下图13-1所示:
可知,当模型复杂度增大的时候,训练误差会逐渐减小并趋近于0,而测试误差会先减小到最小值后又反向增大。当选择模型复杂度过大时,过拟合问题就会出现。
补充
以下提供NLP序列句子识别标注实例,用以更好理解本节。(以下实例以帮助读者理解为旨要,假设可能不是特别严谨)
训练数据集T={(南 B),(海 I),(是 I), (中 I),(国 I),(领 I), (土 I),(。 O) }未知数据P={(不 B), (容 I),(争I),( 议 I),(。 O)}采用BIO标注,B代表句子开始,I代表中间连续词,O代表句子结束。假设采用模型M识别, M次多项式的模型
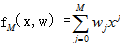
完成下面句子识别。
结果分析:
M=0时候,模型一个常数效果很差,识别如下:

M=1时候,模型一条直线效果很差,识别如下:
M=3时候,模型曲线拟合基本合理,且未知数据预测较好,识别如下:

M=9时候,模型一条直线效果很差,识别如下:

训练数据集:

实验可知:左侧为训练模型的数据,右侧为测试模型的数据。当M=0时,训练误差和测试误差都很大;当M=1时,训练误差和测试误差较大;当M=3时,训练误差比M=9的训练误差大,总体训练误差还好,但是预测误差却小于M=9时的预测误差。综合比较,选择M=3的模型效果会更好。
模型评估与选择
模型评估的概念
评估准确率的常用技术:保持和随机子抽样、K-折交叉验证、自助方法
统计显著性检验:评估模型准确率
ROC曲线:接收者操作特征曲线比较分类器效果好坏
模型评估的评测指标
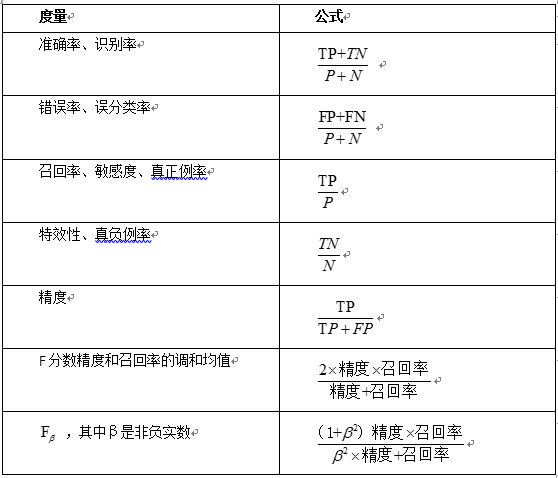
混淆矩阵:正元组和负元组的合计。详细如表13-1所示:
注意:学习器的准确率最好在检验集上估计,检验集由训练集模型未使用的含有标记的数据构成。
各参数描述如下:
TP(真正例/真阳性):是指被学习器正确学习的正元组,令TP为真正例的个数。
TN(真负例/真阴性):是指被学习器正确学习的负元组,令TN为真负例的个数。
FP(假正例/假阳性):是被错误的标记为正元组的负元组,令FP为假正例的个数。
FN(假负例/假阴性):是被错误的标记为负元组的正元组,令FN为假负例的个数。
高准确率的学习模型:大部分元组应该在混合矩阵的对角线上,而其他为0或者接近0,即FP和FN为0。其本质上是一个对角矩阵时准确率最高。
准确率:正确识别的元组所占的比例。又叫做识别率,公式如下:
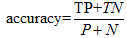

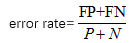 或者1-accuracy(M)
或者1-accuracy(M)
检验时,应采用检验集未加入训练集的数据。当采用训练集估计模型时,会再带入误差,这种称为乐观估计。准确率可以度量正确标注的百分比,但是不能正确度量错误率。诸如样本不平衡时,即负样本稀疏的时候。比如:欺诈、癌症等,这种情况下应使用灵敏性特效性度量。
灵敏度又叫真正识别率:正确识别的正元组的百分比,公式如下:
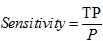
特效性又叫真负例率:正确识别的正元组的百分比,公式如下:
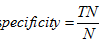
准确率的灵敏度和特效性的函数关系:
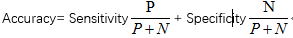
精度:精确性的度量即标记为正元组实际为正元组的百分比,公式如下:
、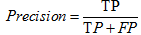
召回率:完全性的度量即正元组标记为正的百分比,公式如下:
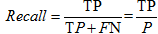
精度和召回率之间趋向于逆关系,有可能出现一个指标降低另一个指标提升的情况。此刻两个指标预想达到综合引出了F度量值
F度量(又叫F分数):用精度和召回率的方法把他们组合到一个度量中。公式如下:


比较:F度量是精度和召回率的调和均值,赋予精度和召回率相等的权重,  度量是精度和召回率加权度量,它赋予召回率权重是精度的β倍。诸如中文词汇中常用词的权重比生僻词的权重大,而这也符合实际应用。
度量是精度和召回率加权度量,它赋予召回率权重是精度的β倍。诸如中文词汇中常用词的权重比生僻词的权重大,而这也符合实际应用。
注意:当元组属于多个类时,不适合使用准确率。当数据均衡分布即正负元组基本相当时,准确率效果最好,而召回率、特效性、精度、F和 更适合于样本分布不均的情况。
## 模型评估的几种方法 模型评估包括多种方法,常见的评估流程如图13-2所示。
2)K-折交叉验证评估准确率:(建议10折)
K-折交叉验证:将初始的数据随机分为大小大致相同的K份,训练和检验进行K次,如第1次迭代第一份数据作为检查集,其余K-1份作为训练集,第2次迭代。第二份数据作为检验集,其余K-1份作为训练集,以此类推直到第K份数据作为检验集为止。此方法每份样本用于训练的次数一致且每份样本只作为一次检验集。准确率是K次迭代正确元组总数除以初始数据元组总数。一般建议采用10-折交叉验证估计准确率,因为它的偏移和方差较低。
3)自助法评估准确率:
自助法有放回的均匀抽样,常用632自助法。即63.2%原数据将出现在自助样本中。而其余38.8%元数据形成检验集。
ROC曲线比较学习器模型
成本效益(风险增益):如错误的预测癌症患者没有患病比将没有患病的病人归类癌症的代价大等等事件,据此给予不同的权重。
ROC曲线又叫接受者操作特征曲线,比较两个学习器模型的可视化工具,横坐标参数假正例率,纵坐标参数是真正例率。以此汇聚成的曲线,越靠近对角线(随机猜测线)模型越不好。
真正例率(召回率):
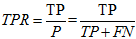
假正例率:
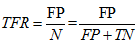
实例解析:以10个检验元组的概率分类器为例绘制ROC曲线。数据如表13-4所示
由以上数据绘制ROC曲线如图13-3所示:
由此可知,对角线为随机猜测线,模型的ROC曲线越靠近对角线,模型的准确率越低。如果很好的模型,真正比例比较多,曲线应是陡峭的从0开始上升,后来遇到真正比例越来越少,假正比例元组越来越多,曲线平缓变的更加水平。完全正确的模型面积为1。</p>
参考文献
完整代码下载
源码请进【机器学习和自然语言QQ群:436303759】文件下载:
作者声明
本文版权归作者所有,旨在技术交流使用。未经作者同意禁止转载,转载后需在文章页面明显位置给出原文连接,否则相关责任自行承担。


